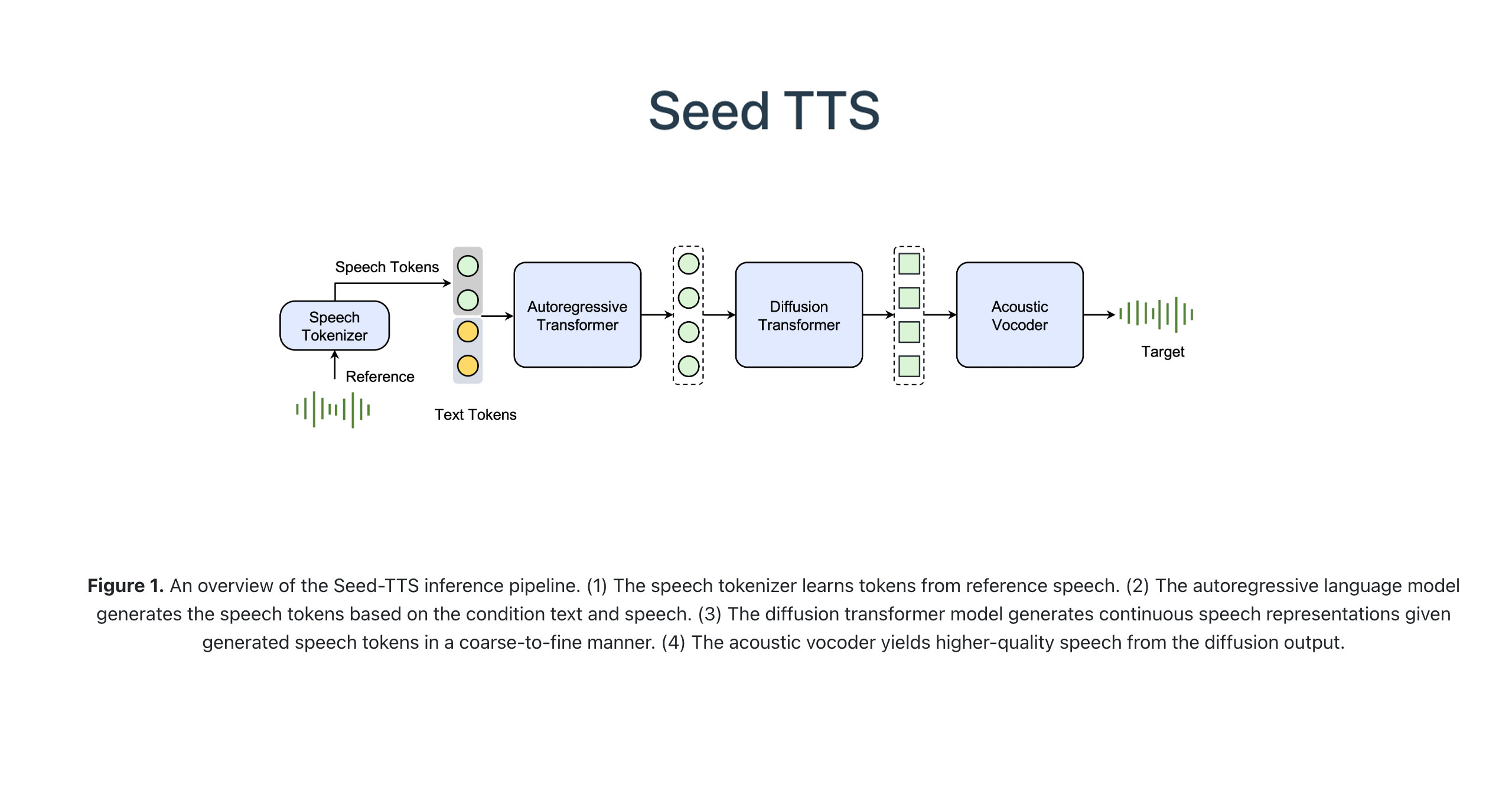
Seed TTS
열기 Seed TTSSeed TTS은(는) 무엇인가?
The Seed-TTS model series has been unveiled, marking a significant advancement in text-to-speech technologies. These sophisticated autoregressive models are crafted to produce speech remarkably akin to that of humans, setting a new benchmark for foundational speech generation systems. Notably proficient in contextual speech learning, Seed-TTS attains a level of speaker likeness and authenticity that rivals actual human speech, as affirmed by both objective metrics and subjective assessments. When fine-tuned, the model's perceived quality soars even further. A standout feature of Seed-TTS is its exceptional ability to fine-tune speech qualities, including emotional expression, granting it the flexibility to create varied and rich vocal expressions for any speaker profile. In addition, the developers have innovated with a novel self-distillation method meant to streamline speech, as well as employing reinforcement learning strategies to bolster model stability, likeness to the intended speaker, and overall controllability. Beyond the core model, the Seed-TTS repertoire expands with the introduction of Seed-TTSDiT—a non-autoregressive variant that forgoes traditional reliance on fixed phoneme timing. Instead, it utilizes a progressive diffusion-led architecture, enabling streamlined, end-to-end speech synthesis. Impressively, Seed-TTSDiT matches the language model-based Seed-TTS in rigorous testing, proving its worth in speech editing scenarios and highlighting the potential to transform the text-to-speech landscape permanently.